letter: s frequency: 3
letter: t frequency 3
letter: a frequency 1
letter: e frequency 1
letter: h frequency 1
letter: i frequency 2
letter: frequency 3
Then we have to create a binary tree, this could be done by sorting this list by frequency and making the two lowest elements into leaves, creating a parent node with a frequency that is the sum of the two lower element's frequencies. The two elements are removed from the list and the new parent node is inserted into the list by frequency and we have to sort the list again and repeat this process until the there is only one element left in the list, that is the root.

The idea behind Huffman coding is based upon the frequency of a symbol in a sequence. The symbol that is the most frequent in that sequence gets a new code that is very small, in the other hand the symbols that have a small frequency will get a code that is very long.
In my first attempt I was using only list and dictionaries but I get a mess when a I want to get the code of each letter because every time I have 2 nodes with the same value the tree traversal take wrong turns; so I decide to use a structure to create every node. With this structure I know which letter it has, its frequency, its code and the node that is on its left branch and on its right branch.
This implementation was simpler to traverse the tree but at first for me it was confused because I didn't know how to print every node.
This is my implementation in python:
This are some of the tests:
 |
| Test text: This is a test |
 |
| Test text: I would trade all my technology for an afternoon with Socrates. |
 |
| Test text: I would trade all my technology for an afternoon with Socrates. |
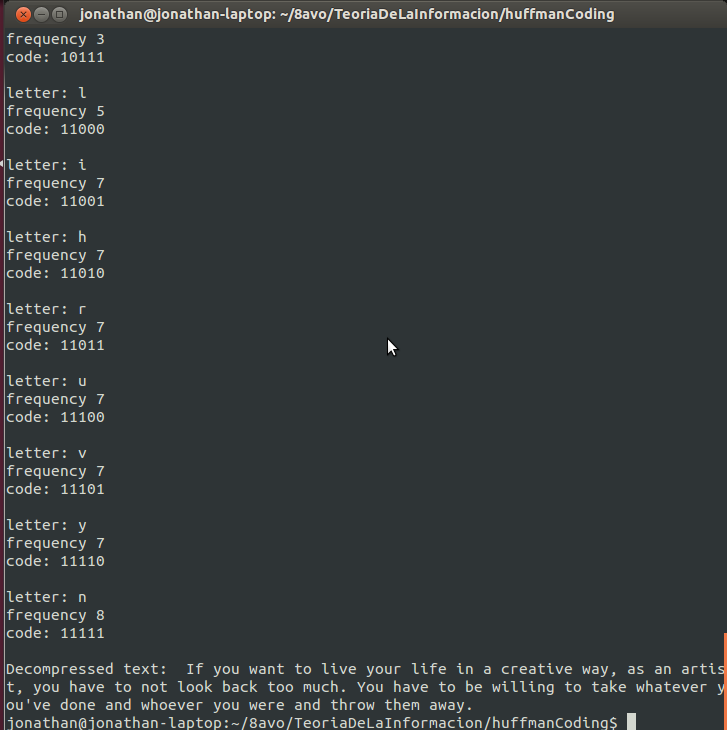 |
| Test text: If you want to live your life in a creative way, as an artist, you have to not look back too much. You have to be willing to take whatever you've done and whoever you were and throw them away. |
No estás en realidad pasado la salida a algo ni sacando tasas de compresión... El reporte no corresponde a lo que se esperaba. 6+4 pts.
ReplyDelete