- One or more management servers (nodes MGM)
- One or more database / storage nodes (DB nodes)
- One or more applications (API nodes)
Node MGM
This kind of node performs the function of managing, controlling and coordinating the other nodes within the cluster. Implements data configuration functions, start or stopother nodes within the cluster, perform backups, or other administrative tasks. Because it controls and shapes the rest of the nodes must be started before any other nodes
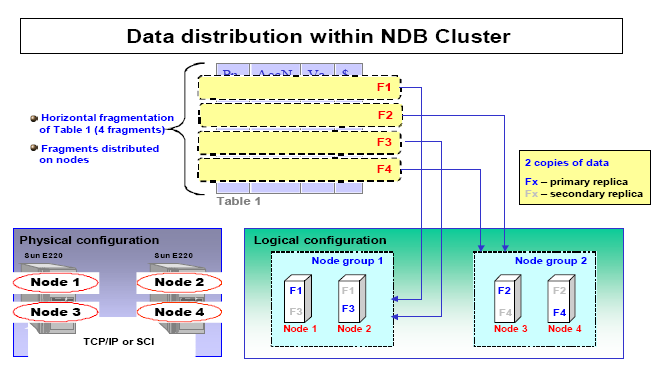
DB nodes
This type of node stores the data. The number of nodes in this type within the cluster is equal to a number of replicas by the number of fragments, for example, handled 4 replicas of the data with 2 fragments would require 8 data nodes. No need to handle more than one replica.API Nodes
This nodes are used to access cluster data.
How it operates?
- Data is synchronously replicated between storage nodes, this minimizes problems of falls by fail-over.
- The nodes are designed using an shared-nothing architecture.
- No failure points (points of failure). Any node can be deleted without loss of data exist and without stopping the applications that use the base.
- The use of SQL is transparent which simplifies the work of developers and DBAs.
- Applications connect to the server regardless of specific details of how information is stored or such as network connections.
- This allows an application to be "portable" between environments where there is or not and where there is replication or clustering.

Shared nothing architecture
Is a distributed computing architecture in which each node is independent and self-sufficient, and there is no single point of contention across the system. More specifically, none of the nodes share memory or disk storage.Node and System Recovery
- When a node has a fault, to recover all information restores the help of other nodes.
- As in the version without cluster, error logs and it handles that keep the inf complete and consistent
- The cluster uses "based on pessimistic locking concurrency controls."
Concurrency Control
NDB Cluster uses pessimistic concurrency control based on locking. If a requested lock (implicit and depending on database operation) cannot be attained within a specified time, then a timeout error occurs.Concurrent transactions (for example parallel application programs, thread-based applications, or applications with asynchronous transactions) sometimes deadlock when they try to access the same information. Applications need to be programmed so that timeout errors occurring due to deadlocks are handled. This generally means that the transaction encountering timeout should be rolled back and restarted.
Example:

8 pts for the lab
ReplyDelete