El sistema que analizaré es el de mi proyecto, que como ya saben trata sobre el control de temperatura de un cautín.
Los objetivos para esta entrega son los siguientes:
- Conocer cuánto tarda en estabilizarse nuestro sistema al introducirle perturbaciones.
- Analizar cuánto le cuesta al sistema estabilizarse.
- En nuestro caso, graficar temperatura vs tiempo.
Primero que nada, por qué es importante la estabilidad?
La estabilidad es una la propiedad que caracteriza los sistemas dinámicos y es la que se considera más importante de todas, ya que, si un sistema no es estable, normalmente carece de interés y utilidad.Al hablar de estabilidad en sistemas dinámicos, se refiere a que el sistema actúe de manera normal o lo mejor posible aun y cuando se introduzcan o le lleguen pequeñas perturbaciones en las condiciones iniciales o en alguna de las variables que intervienen en la ecuación que describe al sistema.
De acuerdo a Lyapunob, un punto de equilibrio de un sistema dinámico es estable si todas las soluciones que nacen en las cercanías del punto de equilibrio permanecen en dichas cercanías; de otra forma resulta inestable
Para realizar esta tarea, observé las funciones de transferencia de los compañeros de mi equipo y platicando con ellos llegamos a la conclusión de que necesitábamos modificar la función, y debido a esto la función de transferencia cambió a la siguiente:

Como pueden observar la función tuvo algunos cambios, hubo un cambio al sustituir Corriente*Resistencia por Voltaje (V) esto lo hicimos utilizando la ley de Ohm. También pueden observar que hay una multiplicación de Potencia por Temperatura, dicha potencia en el programa en Octave se obtiene multiplicando la corriente de entrada por el voltaje que se obtiene.
Este es el código en Octave:
Aquí las gráficas que obtuve con distintos valores. Cabe aclarar que los valores que cambié en las distintas pruebas son Corriente y Voltaje, ya que cualquier cambio en el potenciómetro cambiará forzosamente estas dos variables:

T=77, Q=20, V=30, I=2

T=60, Q=20, V=10, I=0,5

T=55, Q=20, V=40, I=1

T=30, Q=20, V=80, I=1.5
Al observar las gráficas podemos concluir que las diferencias de temperatura más grandes llevan un mayor tiempo en estabilizarse, aunque este cambio no es muy grande si se observan las temperaturas bajas.
Las pruebas anteriores son sin provocar ruido a la función de transferencia, para agregar una distorsión utilicé la librería lsim, a esta función se le pasa como parámetros la función de transferencia, una ecuación que provoque la distorsión y el tiempo.
Este es el código:
Aquí algunos de los resultados:
Las pruebas anteriores son sin provocar ruido a la función de transferencia, para agregar una distorsión utilicé la librería lsim, a esta función se le pasa como parámetros la función de transferencia, una ecuación que provoque la distorsión y el tiempo.
Este es el código:
Aquí algunos de los resultados:

T=77,Q=20,V=30,I=2
La distorsión causada por la función e^(-t)

T=77,Q=20,V=30,I=2
La distorsión causada por la función cos(-t)

T=55,Q=20,V=40,I=1
La distorsión causada por la función cos(-t)
En conclusión, observando estas últimas gráficas podemos observar que al sistema le cuesta trabajo recuperarse cuando algo le provoca ruido, en ciertos casos si logra recuperarse pero en otros le cuesta mucho














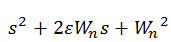






















.png)